前一篇介紹完資料庫第一正規化,如果有按照文章操作的應該會發覺,執行完第一正規化後的資料表,可能還是有許多的重複資料浪費儲存空間,這時我們就需要第二正規化來解決這些問題。
第二正規化(2NF)
執行第二正規化有三個核心概念:
- 確保資料表已經符合第一正規化
- 資料表中所有非主鍵的欄位屬性需完全功能相依於主鍵。如有非完全功能相依的欄位需分割出去,組成新的資料表
這邊出現了一個的新名詞- 功能相依,是什麼意思呢? 以下圖為例,我們設定主鍵為sku(產品編號),product_name(產品名稱)欄位值如果是被sku欄位決定的話,我們稱product_name欄位功能相依於主鍵sku欄位。
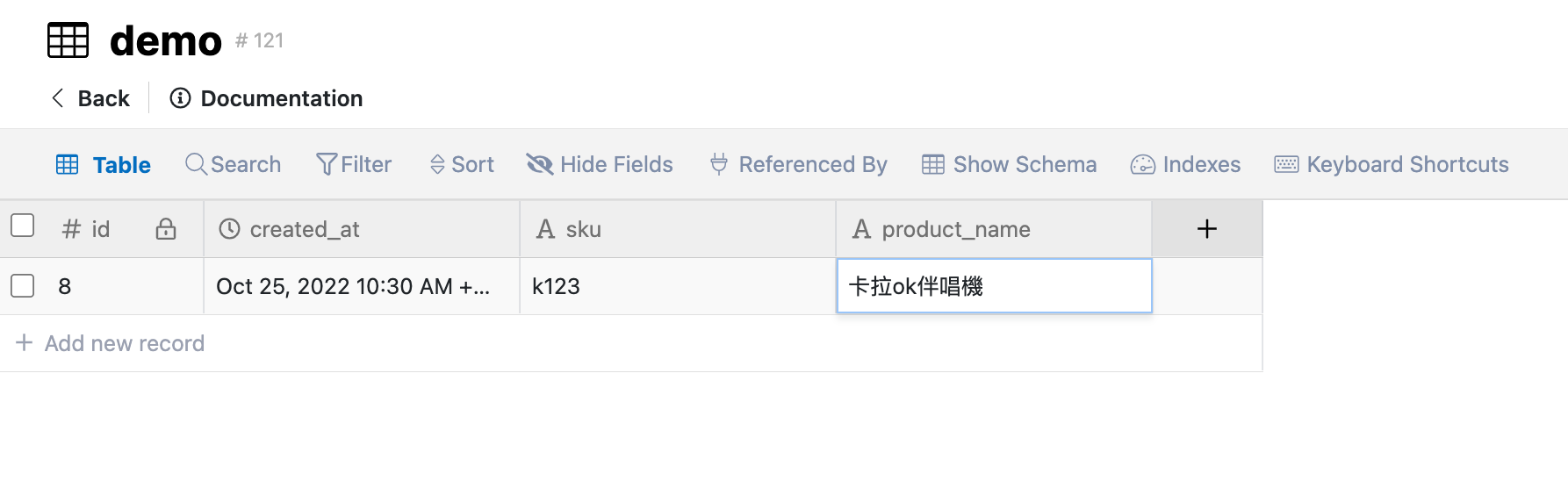
我們以一張簡單的訂單資料表為例,order_id(訂單編號)是這張表的主鍵,如果逐一欄位檢視相依性,應該能發現product_name欄位值是由sku欄位所決定、buyer_phone欄位是由buyer_name欄位所決定,與order_id欄位沒有功能相依。仔細看這些欄位的資料也重複地出現在資料表,造成了儲存空間的消耗。
更麻煩的是當我們要修改sku對應的product_name時,需要把所有符合條件的紀錄都抓出來逐一修改,相當耗時也不容易維護,萬一有少修改到的紀錄,更會造成資料不一致的困擾。
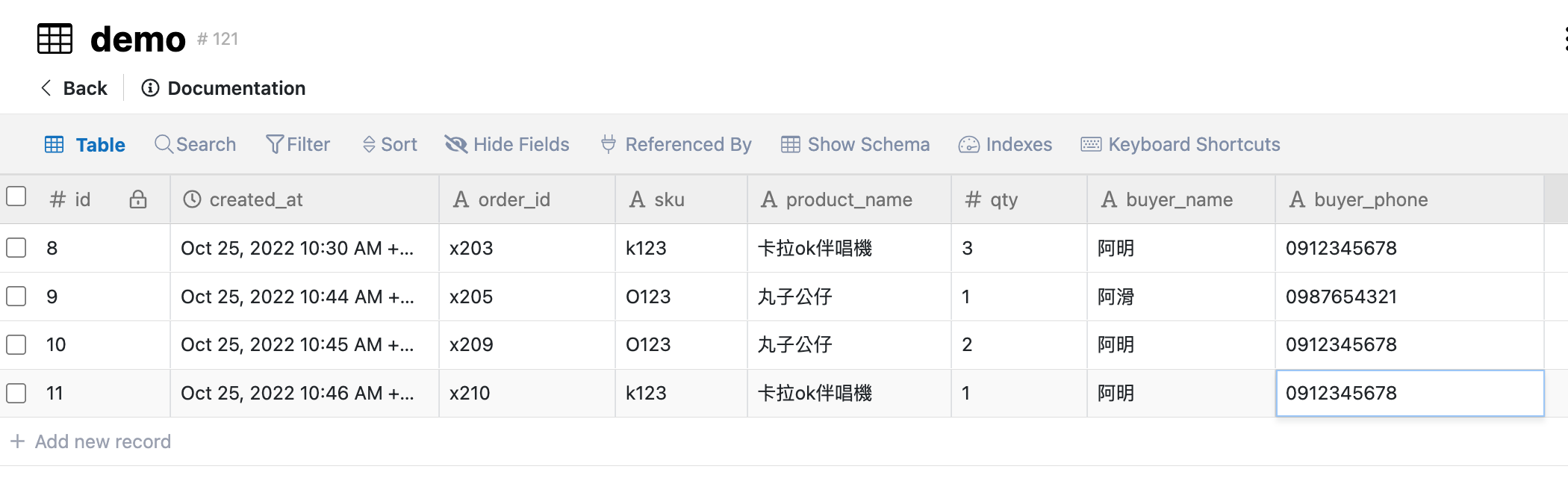
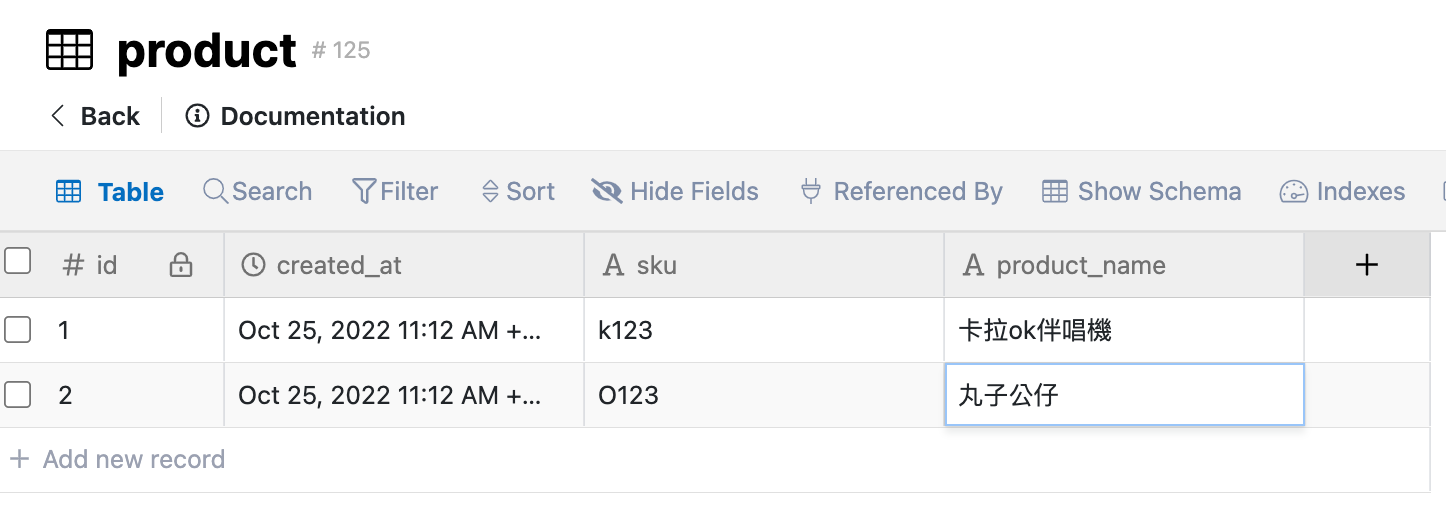
為了解決這個問題我們需要將訂單資料表做拆分,首先我們可以將sku及product_name拉出組成一張產品資料表,並以sku為主鍵。
完成後的訂單資料表就可以將product_name欄位移除,留下sku欄位作為外來鍵,當查詢訂單資料表需要取得product_name 資料時,可以運用sku外鍵欄位與產品資料表的主鍵sku欄位作關聯查詢。而這種主鍵與外鍵的配對產生的關聯性,也是為什麼被稱為關聯式資料庫的原因。
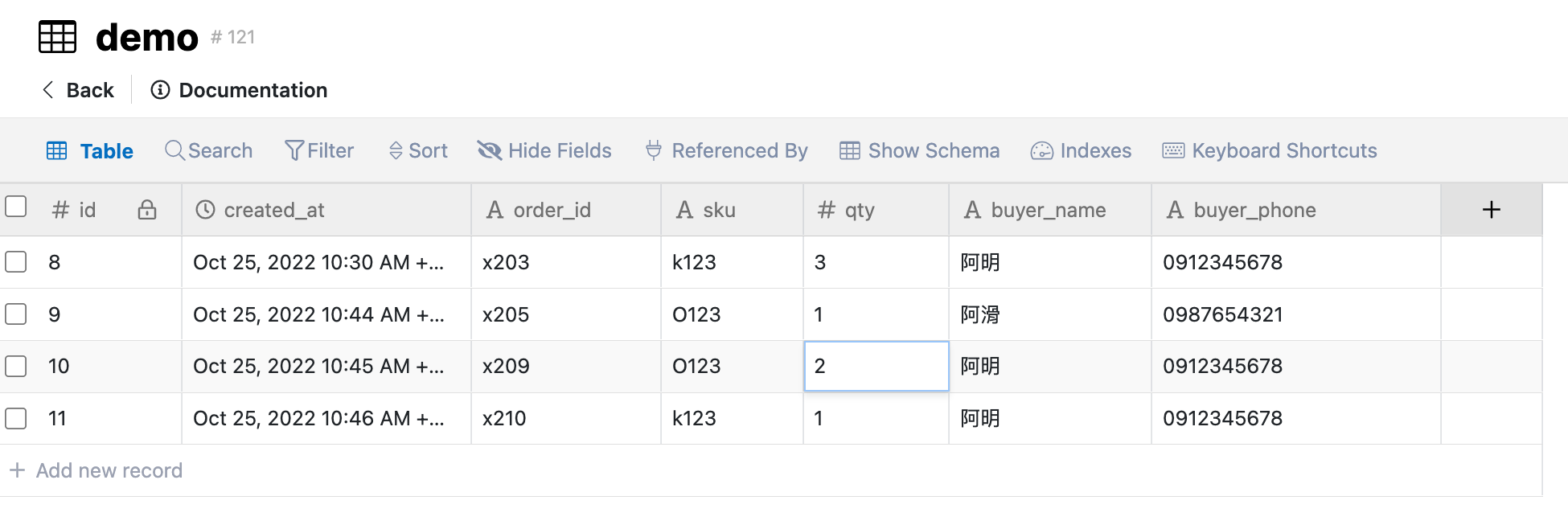
總結第二正規化的目的,是讓我們我們檢視資料表中每個欄位與主鍵的關係,把非功能相依的資料欄位另開資料表儲存。運用資料表間主鍵與外鍵的關聯性,來降低資料表內資料儲存的重複性及修改資料操作錯誤發生的可能性。
到目前為止完成資料庫的正規化只差一步之遙了,最後我們將為大家介紹資料庫的第三正規化,只要將這三個正規化完成,就能大幅提升資料表的儲存效能喔。